42 - Google Hacking - 08/07/2006
Autor: Lic. Cristian F. Borghello
En boletines anteriores hemos tratado desde diversos enfoques la forma en que Google indexa su información. En esta oportunidad hablaremos de la forma de encontrar de manera eficiente la información que Google recolecta a través de sus robots. Si bien puede pensarse en Google Hacking como una acción contra el buscador para realizar algún ataque sobre él, nada más alejado de la realidad. Se llama Google Hacking al "arte" de usar la potencial de Google para recolectar información que debería ser privada, ingresar a directorios, revelar información como usuarios y passwords, realizar análisis de sitios y seguridad de los mismos.
Ante todo empecemos por comprender como funciona Google, el cual ya dispone de su propio verbo "googlear" según el el diccionario Merrian-Webster Collegiate Dictionary de EE.UU.
La ventaja fundamental de este buscador con respecto a otros es el algoritmo utilizado, el cual se basa en complejas funciones matemáticas, mejoradas día a día, que tienen como objetivo obtener la posición que cada página debe ocupar en el ranking.
Además esta posición se basa en una valoración objetiva de la importancia de la página web a buscar y es el resultado de una ecuación matemática compuesta por más de 500 millones de variables y 3.000 millones de términos. Este resultado es un número de 0 a 10 que representa la importancia que una página web tiene en Internet y recibe el nombre de PageRank.
Por último diremos que Google dispone de robots llamados Googlebots que se encargan de almacenar cada sitio web e indexarlo en las bases de datos de Google. Es decir que nuestro amigo funciona como un inmenso repositorio de nuestras webs.
En la img_01 puede verse la última vez que el robots de Google ha revisado Segu-Info, la cantidad de páginas indexadas y la cantidad de MegaBytes de información almacenados en su base de datos. Esta base tiene dos objetivos:
{kind=link}
- realizar las búsquedas sobre ella para evitar la búsqueda en los sitios reales, con la pérdida de performance asociada.
- permitir visualizar las páginas que ya no están online pero han sido indexadas en alguna oportunidad. Esta funcionalidad recibe el nombre de caché.
Google no es más que un gran procesador de comandos (que son cada vez más) y mejor sea la combinación en que los usemos, mejores serán los resultados obtenidos. Como todos sabemos si colocamos una palabra en el cuadro de texto, Google entenderá que debe realizar la búsqueda de esa palabra. Pero si colocamos: (e^(i * pi)) + 1
Google entenderá que deseamos realizar una operación matemática (la entidad de Euler, la fórmula más importante del mundo) y nos dará el resultado de la misma que es 0 (cero) en este caso.
Si nuestro objetivo es la (in)seguridad de la información podemos comenzar a refinar nuestras búsquedas con el fin de obtener información que no debió ser publicada, que ha sido publicada por administradores descuidados o bien que la misma ya no se encuentra disponible en forma online pero lo estuvo hace tiempo (uso de la caché).
Otra de las ventajas de las que disponemos utilizando Google es que podemos realizar un perfil completo de una organización en forma pasiva, es decir sin utilizar técnicas de ataque intrusivo sobre los servidores de la misma. Esto en sí mismo es una ventaja ya que es una técnica indetectable, absolutamente legal y transparente.
Para comenzar nuestra búsqueda lo primero que deberemos conocer son los comandos disponible. Para ello recomiendo la lectura de "Google, factoría de ideas", disponible en nuestra sección de libros.
Existen errores que suelen cometerse muy a menudo y ahí esta Google para recordarnoslo:
- Configurar un sitio web es trivial y sólo consiste en levantar ciertos servicios en el servidor.
- Instalar un servidor web consiste en instalar cierto servicios y dejar la configuración predeterminada.
- Instalar un Sistema Operativo es trivial y la instalación por defecto es la recomendada.
- Instalar, verificar el funcionamiento y por último borrar los archivos innecesarios
Cometer estos errores tienen un alto precio ya que una vez que nuestro sitio web sea indexado comienza a valer el dicho: "lo que ingresa a Internet nunca vuelve a salir".
Un proyecto muy interesante sobre búsquedas posibles es el llevado adelante por Johnny "j0hnny" Long, quien además a publicado libros sobre este tema.
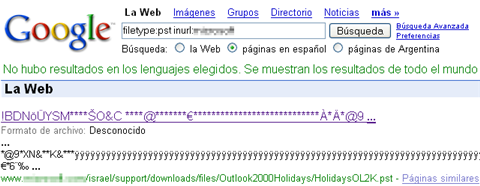
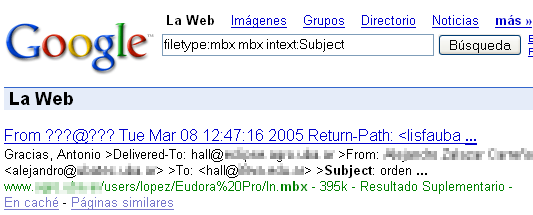
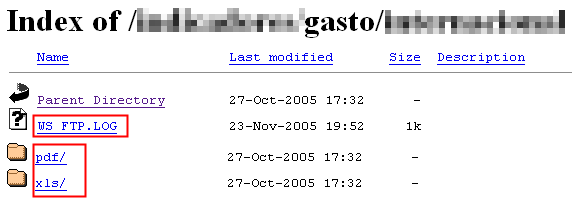
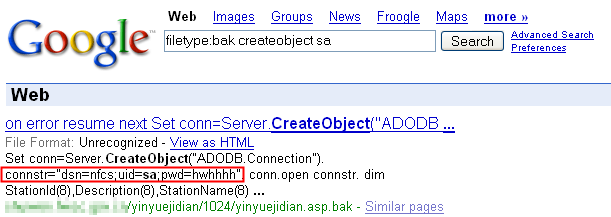
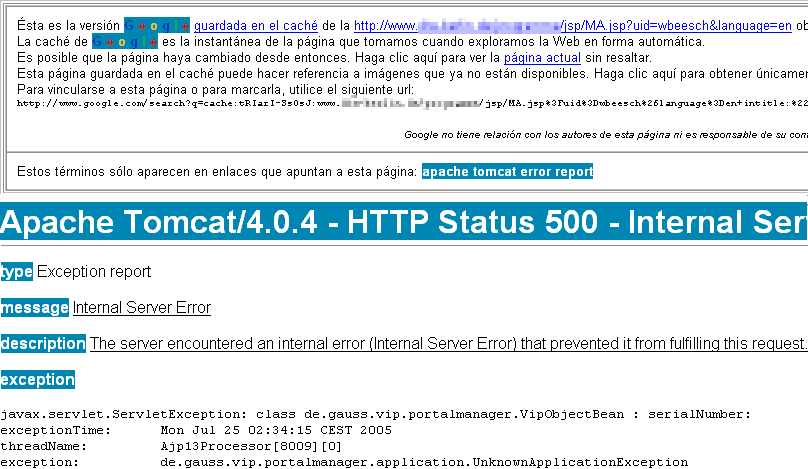
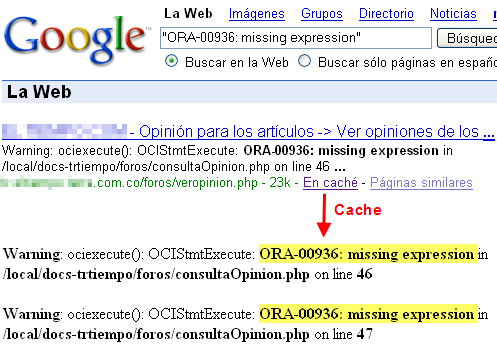
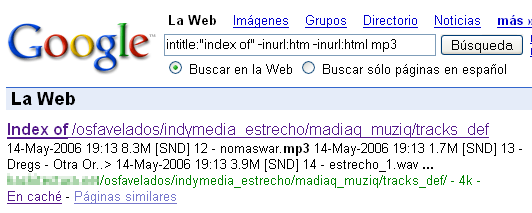
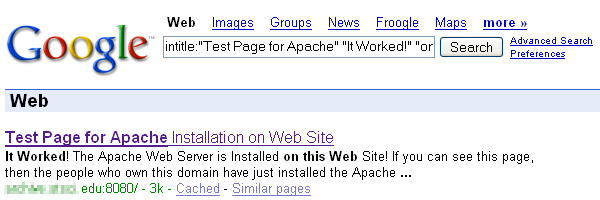
A continuación ejemplificaremos cada uno de los casos mencionados con sencillas búsquedas que nos devolverán archivos que nunca deberían haberse publicado:
- Archivos que nunca deberían haber sido publicados
- Archivos que ya no existen pero permanecen en caché
- Configuraciones por defecto
- Errores de configuración
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
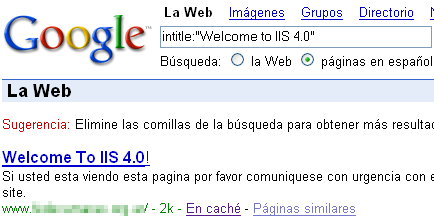{kind=link}
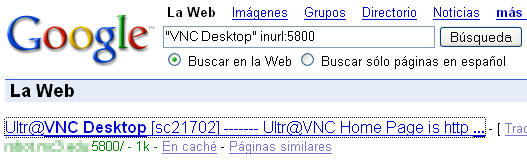{kind=link}
Como podemos ver la combinación puede ser infinita y realmente nos podemos llegar a asombrar sobre la diversidad de la información que podemos encontrar ya sea que esta haya sido publicada intencionalmente o no. Es imprescindible que los administradores y los directivos de las organizaciones tomen conciencia de la importancia de la información, sea este un importante documento sobre cotizaciones como un archivo de logs de una aplicación. Sea cual sea el origen de este archivo el dueño de datos siempre debe evaluar si el mismo debe publicarse. Si el documento es publicado sin la debida evaluación previa, esto significa una gran vulnerabilidad que tarde o temprano será objeto de explotación por un tercero.
Más Información:
Sobre Google
http://es.wikipedia.org/wiki/Google
http://google.dirson.com/
Google, factoría de ideas
http://zabalnet.diocesanas.org/google/google.pdf
Sitio de Johnny "j0hnny" Long
http://johnny.ihackstuff.com/
Libro sobre Google Hacking
http://www.segu-info.com.ar/libros
Boletines sobre Google
https://www.segu-info.com.ar/articulos/boletin_060318.htm
https://www.segu-info.com.ar/articulos/boletin_060312.htm
Buenos Aires, 08 de julio de 2006